在本次实验中我们需要自己去实现网卡驱动和网络套接字,在写网卡驱动前我们需要知道网卡收发包的工作原理,再看了文档和查阅了一些资料之后总结了一下。
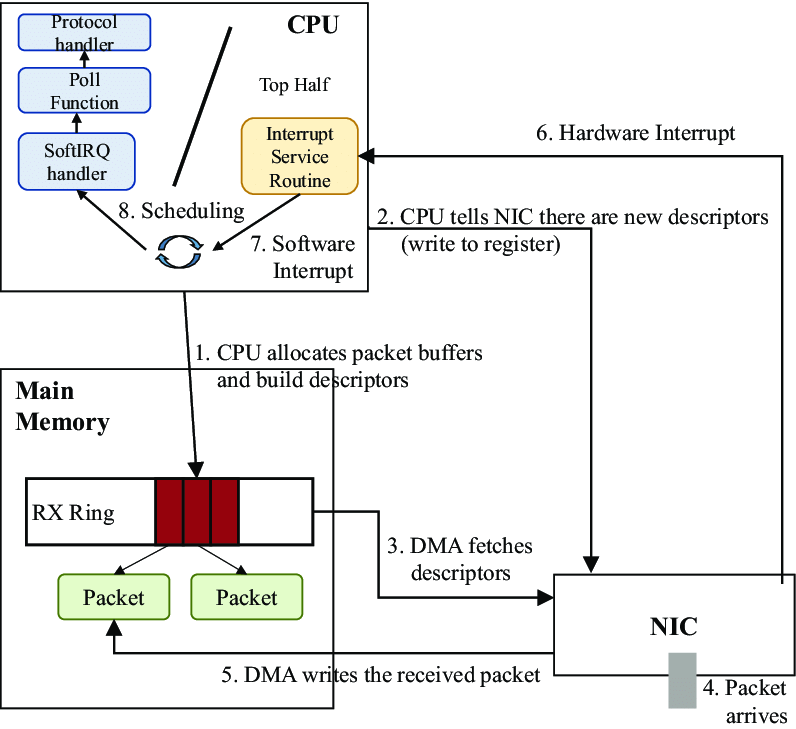
由这张图我们可以梳理下关于网卡收发包的细节,首先内核需要分配 rx_ring 和 tx_ring 两块环形缓冲区的内存用来接收和发送报文。其中以太网控制器的寄存器记录了关于 rx_ring 和 tx_ring 的详细信息。接收 packet 的细节如下:
内核首先在主存中分配内存缓冲区和环形缓冲区,并由 CPU 将 rx_ring 的详细信息写入以太网控制器
随后 NIC (Network Interface Card) 通过 DMA 获取到下一个可以写入的缓冲区的地址,当 packet 从硬件收到的时候外设通过 DMA 的方式写入对应的内存地址中
当写入内存地址后,硬件将会向 CPU 发生中断,操作系统检测到中断后会调用网卡的异常处理函数
异常处理函数可以通过由以太网控制寄存器映射到操作系统上的内存地址访问寄存器获取到下一个收到但未处理的 packet 的描述符,根据该描述符可以找到对应的缓冲区地址进行读取并传输给上层协议。
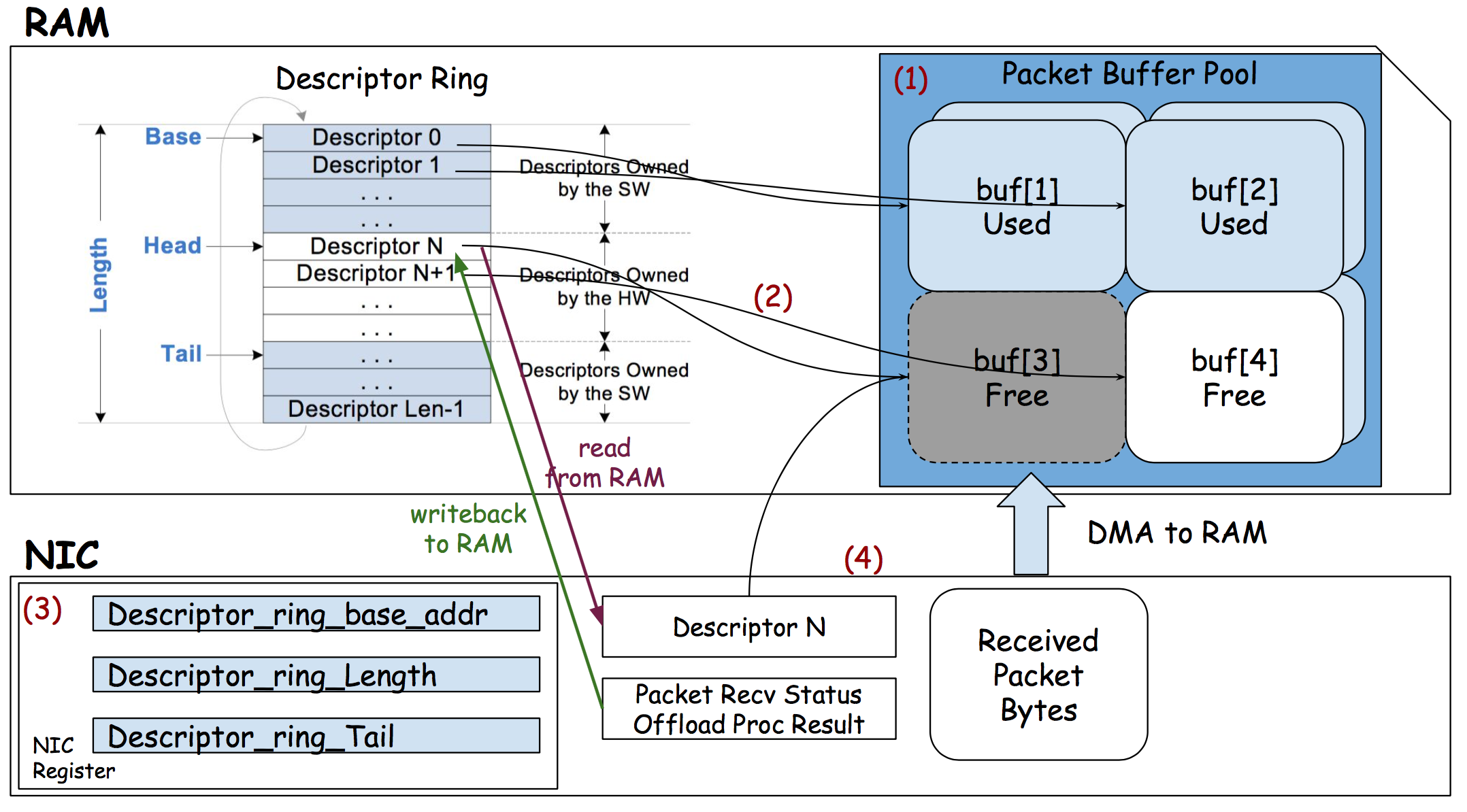
由这张图可以看出软硬件在接收到 packet 的时候是如何工作的,首先硬件通过 DMA 拿到了 Head 所在 rx_ring 描述符的内存地址,并获取到其缓冲区地址,然后将收到的 packet 通过 DMA 拷贝到内存中,随后更新 rx_ring 描述符的内容并向寄存器中写入 HEAD 的新位置,随后向操作系统发出中断,操作系统收到中断通过获取 Tail 所在位置的文件描述符的信息来获取下一个将要处理的 packet,处理后由软件而非硬件更新 Tail 的位置。
所以我们可以按照以下逻辑写一下网卡收包与发包的过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 int e1000_transmit(struct mbuf *m) { // // Your code here. // // the mbuf contains an ethernet frame; program it into // the TX descriptor ring so that the e1000 sends it. Stash // a pointer so that it can be freed after sending. // // 获取 ring position acquire(&e1000_lock); uint64 tdt = regs[E1000_TDT]; uint64 index = tdt % TX_RING_SIZE; struct tx_desc send_desc = tx_ring[index]; if(!(send_desc.status & E1000_TXD_STAT_DD)) { release(&e1000_lock); return -1; } if(tx_mbufs[index] != 0){ // 如果该位置的缓冲区不为空则释放 mbuffree(tx_mbufs[index]); } tx_mbufs[index] = m; tx_ring[index].addr = (uint64)tx_mbufs[index]->head; tx_ring[index].length = (uint16)tx_mbufs[index]->len; tx_ring[index].cmd = E1000_TXD_CMD_RS | E1000_TXD_CMD_EOP; tx_ring[index].status = 0; tdt = (tdt + 1) % TX_RING_SIZE; regs[E1000_TDT] = tdt; __sync_synchronize(); release(&e1000_lock); return 0; } static void e1000_recv(void) { // // Your code here. // // Check for packets that have arrived from the e1000 // Create and deliver an mbuf for each packet (using net_rx()). // // 获取接收 packet 的位置 uint64 rdt = regs[E1000_RDT]; uint64 index = (rdt + 1) % RX_RING_SIZE; // struct rx_desc recv_desc = rx_ring[index]; if(!(rx_ring[index].status & E1000_RXD_STAT_DD)){ // 查看新的 packet 是否有 E1000_RXD_STAT_DD 标志,如果 // 没有,则直接返回 return; } while(rx_ring[index].status & E1000_RXD_STAT_DD){ // acquire(&e1000_lock); // 使用 mbufput 更新长度并将其交给 net_rx() 处理 struct mbuf* buf = rx_mbufs[index]; mbufput(buf, rx_ring[index].length); // 分配新的 mbuf 并将其写入到描述符中并将状态吗设置成 0 rx_mbufs[index] = mbufalloc(0); rx_ring[index].addr = (uint64)rx_mbufs[index]->head; rx_ring[index].status = 0; rdt = index; regs[E1000_RDT] = rdt; __sync_synchronize(); release(&e1000_lock); net_rx(buf); index = (regs[E1000_RDT] + 1) % RX_RING_SIZE; } }
这里要注意在从网卡接收 pakcet 的时候必须从 E1000_RDT 的位置开始遍历并向上层进行分发直到遇到未被使用的位置,因为网卡并非是收到 pakcet 立刻向操作系统发起中断,而是使用 NAPI 机制,对 IRQ 做合并以减少中断次数,NAPI 机制让 NIC 的 driver 能够注册一个 poll 函数,之后 NAPI 的子系统可以通过 poll 函数从 ring buffer 批量获取数据,最终发起中断。NAPI 的处理流程如下所示:
NIC driver 初始化时向 Kernel 注册 poll 函数,用于后续从 Ring Buffer 拉取收到的数据
driver 注册开启 NAPI,这个机制默认是关闭的,只有支持 NAPI 的 driver 才会去开启
收到数据后 NIC 通过 DMA 将数据存到内存
NIC 触发一个 IRQ,并触发 CPU 开始执行 driver 注册的 Interrupt Handler
driver 的 Interrupt Handler 通过 napi_schedule 函数触发 softirq (NET_RX_SOFTIRQ ) 来唤醒 NAPI subsystem,NET_RX_SOFTIRQ 的 handler 是 net_rx_action 会在另一个线程中被执行,在其中会调用 driver 注册的 poll 函数获取收到的 Packet
driver 会禁用当前 NIC 的 IRQ,从而能在 poll 完所有数据之前不会再有新的 IRQ
当所有事情做完之后,NAPI subsystem 会被禁用,并且会重新启用 NIC 的 IRQ
回到第三步
而本次实验使用的是 qemu 模拟的 e1000 网卡也使用了 NAPI 机制。
在类 Unix 操作系统上面,设备、pipe 和 socket 都要当做文件来处理,但在操作系统处理的时候需要根据文件描述符来判断是什么类型的文件并对其进行分发给不同的部分进行出来,我们需要实现的就是操作系统对于 socket 的处理过程。
socket 的读取过程需要根据给定的 socket 从所有 sockets 中找到并读取 mbuf,当对应的 socket 的缓冲区为空的时候则需要进行 sleep 从而将 CPU 时间让给调度器,当对应的 socket 收到了 packet 的时候再唤醒对应的进程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 sockrecvudp(struct mbuf *m, uint32 raddr, uint16 lport, uint16 rport) { // // Your code here. // // Find the socket that handles this mbuf and deliver it, waking // any sleeping reader. Free the mbuf if there are no sockets // registered to handle it. // acquire(&lock); struct sock* sock = sockets; // 首先找到对应的 socket while(sock != 0){ if(sock->lport == lport && sock->raddr == raddr && sock->rport == rport){ break; } sock = sock->next; if(sock == 0){ printf("[Kernel] sockrecvudp: can't find socket.\n"); return; } } release(&lock); acquire(&sock->lock); // 将 mbuf 分发到 socket 中 mbufq_pushtail(&sock->rxq, m); // 唤醒可能休眠的 socket release(&sock->lock); wakeup((void*)sock); } int sock_read(struct sock* sock, uint64 addr, int n){ acquire(&sock->lock); while(mbufq_empty(&sock->rxq)) { // 当队列为空的时候,进入 sleep, 将 CPU // 交给调度器 if(myproc()->killed) { release(&sock->lock); return -1; } sleep((void*)sock, &sock->lock); } int size = 0; if(!mbufq_empty(&sock->rxq)){ struct mbuf* recv_buf = mbufq_pophead(&sock->rxq); if(recv_buf->len < n){ size = recv_buf->len; }else{ size = n; } if(copyout(myproc()->pagetable, addr, recv_buf->head, size) != 0){ release(&sock->lock); return -1; } // 或许要考虑一下读取的大小再考虑是否释放,因为有可能 // 读取的字节数要比 buf 中的字节数少 mbuffree(recv_buf); } release(&sock->lock); return size; }
而写 socket 的过程则更为简单,直接将用户态的数据写入对应的缓冲区并传入下层协议即可:
1 2 3 4 5 6 7 8 9 10 11 12 int sock_write(struct sock* sock, uint64 addr, int n){ acquire(&sock->lock); struct mbuf* send_buf = mbufalloc(sizeof(struct udp) + sizeof(struct ip) + sizeof(struct eth)); if (copyin(myproc()->pagetable, (char*)send_buf->head, addr, n) != 0){ release(&sock->lock); return -1; } mbufput(send_buf, n); net_tx_udp(send_buf, sock->raddr, sock->lport, sock->rport); release(&sock->lock); return n; }
最终要实现关闭 socket 的操作,即将对应的 socket 从操作系统维护的所有的 socket 的链表中删除,并释放其所有缓冲区的空间,最终释放 socket 的空间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void sock_close(struct sock* sock){ struct sock* prev = 0; struct sock* cur = 0; acquire(&lock); // 遍历 sockets 链表找到对应的 socket 并将其 // 从链表中移除 cur = sockets; while(cur != 0){ if(cur->lport == sock->lport && cur->raddr == sock->raddr && cur->rport == sock->rport){ if(cur == sockets){ sockets = sockets->next; break; }else{ sock = cur; prev->next = cur->next; break; } } prev = cur; cur = cur->next; } // 释放 sock 所有的 mbuf acquire(&sock->lock); while(!mbufq_empty(&sock->rxq)){ struct mbuf* free_mbuf = mbufq_pophead(&sock->rxq); mbuffree(free_mbuf); } // 释放 socket release(&sock->lock); release(&lock); kfree((void*)sock); }