Introduction
在 Increasing the Effectiveness of Directory Caches by Deactivating Coherence for Private Memory Blocks 这篇论文中,作者介绍了一种动态预测的方法可以将一些仅仅被一个处理器使用的内存区域弃用一致性协议,从而提高 Cache 性能。
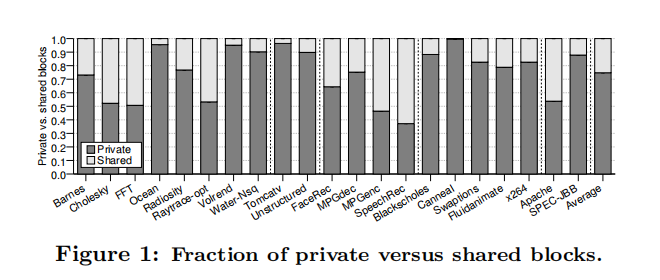
在大部分的共享内存的多核处理器中使用 directory-based 一致性协议,这将不会产生总线带宽不够的情况,但是记录主存中的所有内存块需要使用大量的存储需求。根据研究者的实验发现对于内存中的大部分区域的追踪是没有必要的,因为它们是仅仅被一个核所使用,如果对这些内存不使用一致性协议的话,那么就可以极大地利用 directory-based 的存储空间并提升效率。
Details
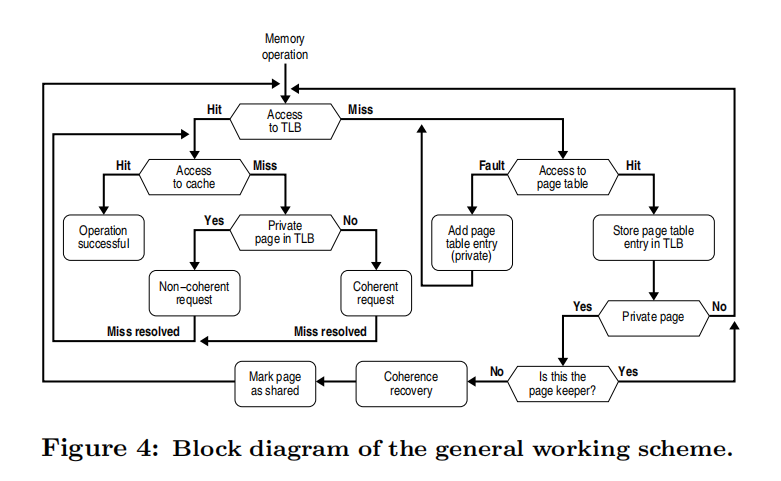
在本篇论文的实现中使用 Page 来管理内存块,因为更加细粒度的内存不好管理。当 Page 第一次从主存中加载进来的时候都被设置为私有的,此时一致性协议是被禁用的,当 OS 检测到私有页变成共享的时候,将会触发一致性协议。这对于操作系统来说不需要做特别大的改动,因为它使用了原有的 TLB,页表,MSHR 等结构。
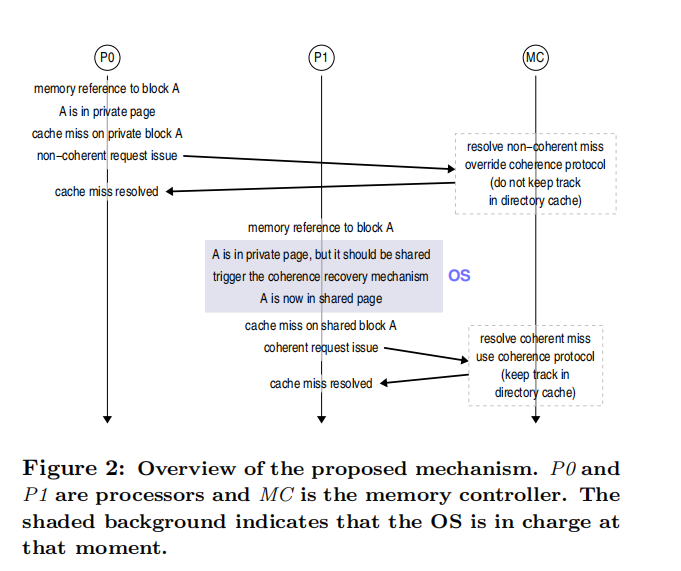
在上述 Figure 2 中举了一个比较简单的例子:首先,P0 处理器向 Cache 请求内存块 A,此时 A 不在 Cache 中,造成 Cache Miss,随后 Cache 从主存中读取内存块 A,此时 A 为私有状态,不使用一致性协议;随后,P1 引用了内存块 A 并且发生了 TLB Miss,当 OS 处理 TLB Miss 的时候将会意识到该页在之前已经被放问过了,随后它将会触发硬件 Cache 一致性策略,并将其状态设置为共享。
为了能够让 OS 对内存进行探测我们需要对 OS 做一些对应的修改。一般来说 TLB Entry 主要包含两部分,一部分是 tag,用来存放虚拟地址,一部分是 data,用来存放物理地址。为了要进行内存探测,我们需要为其加上两位,一位是 private bit§,用于区分该页是私有页还是共享页,另一位是 locked bit(L),用于避免竞态条件。关于 P 位的使用我们上文事实上已经讨论过了,当该页为私有页时,发送非一致性请求,当该页为共享页时,发送一致性请求。
同样地,我们的页表项也需要增加个 3 个 field:private bit §,cached-in-TLB ©, keeper。如果 P 被设置为私有页的话,keeper 将包含其在 TLB 和处理器的标识符;而 C 位则用来表示 keeper 是否有效。在发生 Page Table Fault 之后,OS 将会为其分配一个新的页表项,每当一个新页被加载进来时,P 将被置为 1,C 将被擦除。当 TLB Miss 发生时,处理程序将会在页表中进行搜索,当搜索到的时候,如果 C 是被擦除的表示该页仍然是私有页;如果 P 和 C 都被设置了的话将会去检查该页是否是被共享的。关于标志位的设置的算法如下伪代码所示:
1 | if C is clear then |
除此之外,我们还需要考虑一个问题是,当页状态由私有变为共享时,如何对这部分内存进行恢复呢?在论文中,提及了两种方法,分别被被叫做 Flushing-based Recovery Mechanism 和 Updating-based Recovery Mechanism。
Flushing-based Recovery Mechanism 首先触发一致性恢复的节点将会向涉及了的节点发送恢复请求,在恢复请求到达前,keeper 将执行 3 个操作,首先设置 L 位来锁定对应的 TLB 项;其次,keeper 执行 Cache 查找并更新相关的每个 Cache block,并将数据写回主存;最后,keeper 检查其 MSHR 结构以查看待处理的操作。当任何 Page Block 至少有一个等待的 Miss 或 Evication 时,keeper 必须等待其完成。一旦发生这种情况,相关的块就会被驱逐。之后,keeper 将相应的 TLB 项标记为共享,将其解锁,并通过恢复完成消息通知发起者。
当发起者接收到 recovery 操作完成的消息后,该页被设置为共享页在页表和本地的 TLB 中,在这个过程中,OS 禁止其他处理器访问该页表项,否则将会造成难以预知的结果。下图是该操作的一个示意:
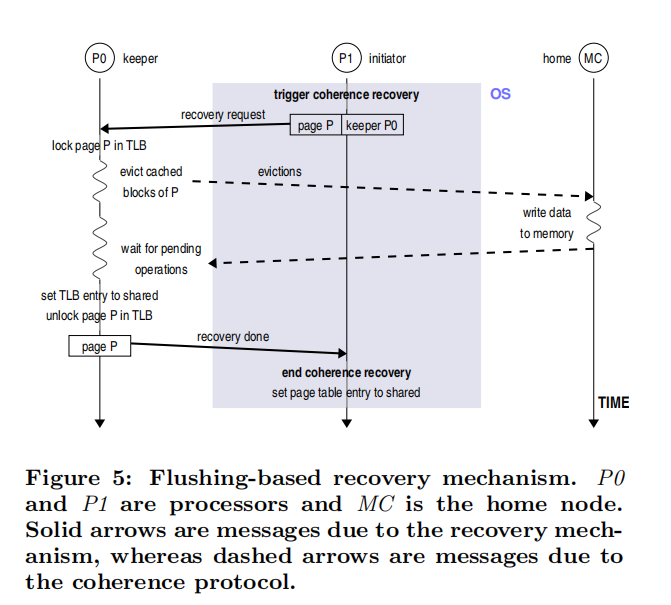
Flushing-based Recovery Mechanism 的方法简单,易于实现,然而缺点是需要去 flush 所有已经被 cached 的块,可能会提高 Cache 的缺失率,从而影响系统性能。为了提供系统性能,该论文提出了 Updating-based Recovery Mechanism 模型来解决问题。
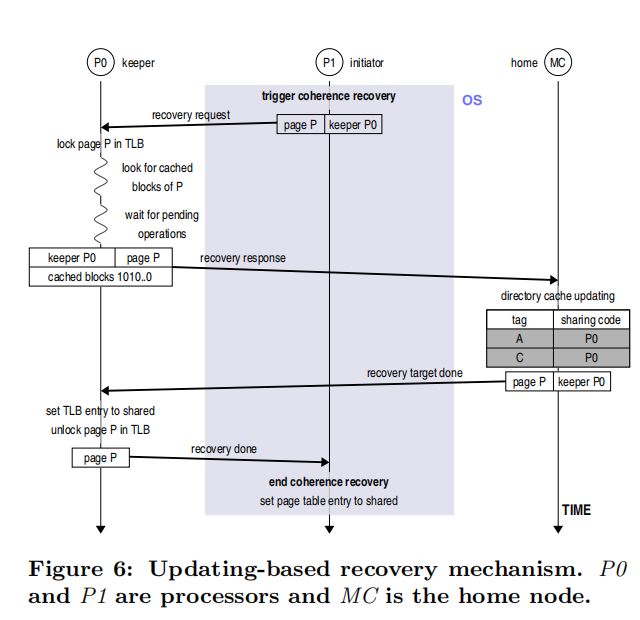
和上一个方法一样,首先由发起节点向 keeper 发起 recovery request。同样在 recovery request 到达 keeper 的时候将会锁住 TLB entry 并且查找到在 Cache 中缓存了的该页的块,这些块的地址将会被编码成为 bit vector,随后一个 recovery response 将被发往 home memory node。为了简单编码被缓存了块的地址,采取类似独热码的方式进行编码,例如第一位编码被设置为 1 表示该页中的第一块被缓存了。在发送 recovery response 之前仍需先要检查 MSHR 寄存器来查看是否有等待的操作,如果有,做完后发送 response,否则直接发送 response。
当 home memory controller 接收到响应后,根据 bit vector 找到对应的地址块,为其在 directory cache 中新建 entry,驱逐老的 entry。当完成后需要发送一条结束消息给 keeper node。
当 keeper node 收到消息后将 TLB entry 解锁并将其设置为共享,并将消息再发送给 initiator(即发送者)。一个简单的示意如下图: