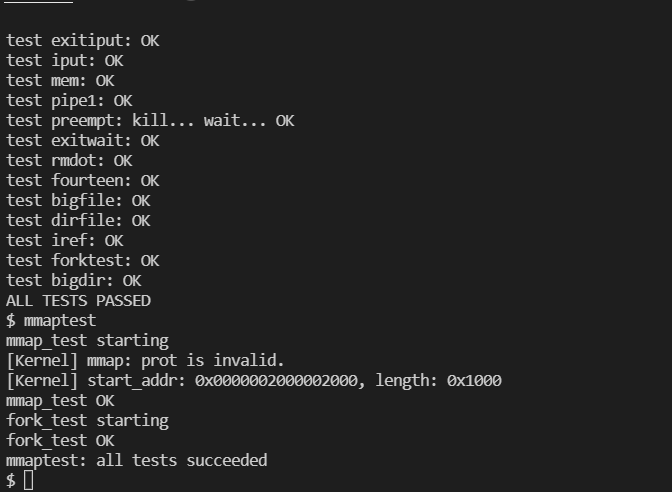
思路相对来说比较简单,copy on write 主要实现是效果是在 fork 的时候并不要为子进程额外分配物理地址,而是与父进程共享物理地址,并且将物理地址的页表项(即最后一级页表项)设为不可写,这样,如果父进程与子进程如果不被写的话就可以完全正常执行,当设计到写操作时,硬件的 MMU 将会检测到页表项不可写,此时会产生 Page Fault 异常,而操作系统在异常处理中需要重新分配私有的物理页,并将原有的物理页拷贝到私有物理页并进行重新映射,并将页表项重新设置为可写即可。而原有的物理页则可能被多个进程所引用,所以由引用计数来决定是否被释放,具体过程见实现部分。
首先用户进程在执行 fork 的时候子进程不需要对父进程物理页面进行实际拷贝,实际修改是在 uvmcopy 这个函数里面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz) { // 将父进程页表内容拷贝到子进程中 // 将所有页表项设置为不可写,这里要模拟一遍页表翻译过程 for(uint64 vaddr = 0; vaddr < sz; vaddr += PGSIZE) { // 我们只需要将最低级的页表加上 COW 标识符 // 并擦去写标志位即可 extern char end[]; pte_t* pte = walk(old, vaddr, 0); uint64 pa = (uint64)PTE2PA((uint64)(*pte)); uint32 index = (pa - PGROUNDUP((uint64)end)) / PGSIZE; pin_page(index); uint64 flags = (PTE_FLAGS((uint64)(*pte)) | PTE_COW) & ~PTE_W; if(mappages(new, vaddr, PGSIZE, pa, flags) != 0){ panic("[Kernel] uvmcopy: fail to copy parent physical address.\n"); } if(pte == 0){ panic("[Kernel] uvmcopy: pte should exist.\n"); } if(!(*pte & PTE_COW)) { // 将页表项加上 COW 标识符 *pte |= PTE_COW; // 清除写标志位 *pte &= ~(PTE_W); } } return 0; }
此时当进程想去去写物理页面的时候会直接触发 Page Fault, 因此我们需要在 usertrap 中进行处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 // // handle an interrupt, exception, or system call from user space. // called from trampoline.S // void usertrap(void) { int which_dev = 0; if((r_sstatus() & SSTATUS_SPP) != 0) panic("usertrap: not from user mode"); // send interrupts and exceptions to kerneltrap(), // since we're now in the kernel. w_stvec((uint64)kernelvec); struct proc *p = myproc(); // save user program counter. p->tf->epc = r_sepc(); // printf("[Kernel] usertrap: epc: %p scause: %p, \n", p->tf->epc, r_scause()); if(r_scause() == 8){ // system call if(p->killed) exit(-1); // sepc points to the ecall instruction, // but we want to return to the next instruction. p->tf->epc += 4; // an interrupt will change sstatus &c registers, // so don't enable until done with those registers. intr_on(); syscall(); } else if(r_scause() == 0xf){ // 发生页错误,此时应当分配页进行重新映射,并添加写标志位 // 获取发生页错误的虚拟地址 uint64 err_vaddr = PGROUNDDOWN(r_stval()); // 对子进程/父进程进行重新映射, 并添加写标志位 // 获取出现页错误的物理地址 pte_t* err_pte = translate(p->pagetable, err_vaddr); if(*err_pte & PTE_COW) { // 如果此时带有 COW 标志位的话 uint64 err_paddr = PTE2PA((uint64)*err_pte); if(err_paddr == 0){ printf("[Kernel] usertrap: err_vaddr: %p\n", err_vaddr); panic("[Kernel] usertrap: fail to walk"); } // 分配一块新的物理页,并将数据拷贝到新分配中的页中 char* page = kalloc(); if(page == 0){ printf("[Kernel] usertrap: Fail to allocate physical page.\n"); p->killed = 1; }else{ // 当拿到发生页错误所在的物理地址时需要进行重新映射 // 此时需要加上写标志位并擦除 COW 标志位 uint64 flags = (PTE_FLAGS((uint64)(*err_pte)) | PTE_W) & (~PTE_COW); // 将原来的数据拷贝到新分配的页中 memmove((char*)page, (char*)err_paddr, PGSIZE); // 对发生错误的虚拟地址重新进行映射 uvmunmap(p->pagetable, err_vaddr, PGSIZE, 1); *err_pte = PA2PTE((uint64)page) | flags; } } }else if((which_dev = devintr()) != 0){ // ok } else { printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid); printf(" sepc=%p stval=%p\n", r_sepc(), r_stval()); p->killed = 1; } if(p->killed) exit(-1); // give up the CPU if this is a timer interrupt. if(which_dev == 2) yield(); usertrapret(); }
除此之外,当进程调用 copyout 函数将数据从内核态拷贝到用户态时我们也需要检查页表项是否有 COW 标志并进行重新分配拷贝页表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 // 拷贝的时候需要查看是否有 COW 标志位进而进行页的重新分配 int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len) { if(dstva > MAXVA){ return -1; } uint64 n, va0; while(len > 0){ va0 = PGROUNDDOWN(dstva); pte_t* pte = translate(pagetable, va0); if(pte == 0){ return -1; } uint64 pa = PTE2PA((uint64)(*pte)); if(*pte & PTE_COW){ char* page = kalloc(); if(page == 0){ panic("[Kernel] uvmcopy: fail to allocate page.\n"); }else{ uint64 flags = (PTE_FLAGS((uint64)(*pte)) | PTE_W) & ~PTE_COW; memmove((char*)page, (char*)pa, PGSIZE); uvmunmap(pagetable, va0, PGSIZE, 1); *pte = PA2PTE((uint64)page) | flags; // kfree((void*)pa); pa = (uint64)page; } } n = PGSIZE - (dstva - va0); if(n > len) n = len; memmove((void *)(pa + (dstva - va0)), src, n); len -= n; src += n; dstva = va0 + PGSIZE; } return 0; }
而对于页面的引用计数我们实现在 kalloc.c 中,我们定义了 pin_page 和 unpin_page 来对页面引用进行修改:
1 2 3 4 5 6 7 8 9 10 11 void pin_page(uint32 index){ acquire(&refs_lock); page_refs[index]++; release(&refs_lock); } void unpin_page(uint32 index){ acquire(&refs_lock); page_refs[index]--; release(&refs_lock); }
在我们使用 kalloc 和 kfree 来分配与释放页面时也需要对引用进行操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 // Free the page of physical memory pointed at by v, // which normally should have been returned by a // call to kalloc(). (The exception is when // initializing the allocator; see kinit above.) void kfree(void *pa) { struct run *r; if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP) panic("kfree"); uint32 index = ((uint64)pa - PGROUNDUP((uint64)end)) / PGSIZE; if(get_page_ref(index) < 1){ printf("[Kernel] kfree: refs: %d\n", get_page_ref(index)); panic("[Kernel] kfree: refs < 1.\n"); } unpin_page(index); int refs = get_page_ref(index); if(refs > 0)return; // Fill with junk to catch dangling refs. memset(pa, 1, PGSIZE); r = (struct run*)pa; acquire(&kmem.lock); r->next = kmem.freelist; kmem.freelist = r; release(&kmem.lock); } // Allocate one 4096-byte page of physical memory. // Returns a pointer that the kernel can use. // Returns 0 if the memory cannot be allocated. void * kalloc(void) { struct run *r; acquire(&kmem.lock); r = kmem.freelist; if(r) kmem.freelist = r->next; release(&kmem.lock); if(r){ memset((char*)r, 5, PGSIZE); // fill with junk // 将引用计数加一 uint32 index = ((uint64)r - PGROUNDUP((uint64)end)) / PGSIZE; // pin_page(index); acquire(&refs_lock); page_refs[index] = 1; release(&refs_lock); } return (void*)r; }