
提高 Directory Cache 性能
Introduction
在 Increasing the Effectiveness of Directory Caches by Deactivating Coherence for Private Memory Blocks 这篇论文中,作者介绍了一种动态预测的方法可以将一些仅仅被一个处理器使用的内存区域弃用一致性协议,从而提高 Cache 性能。
在大部分的共享内存的多核处理器中使用 directory-based 一致性协议,这将不会产生总线带宽不够的情况,但是记录主存中的所有内存块需要使用大量的存储需求。根据研究者的实验发现对于内存中的大部分区域的追踪是没有必要的,因为它们是仅仅被一个核所使用,如果对这些内存不使用一致性协议的话,那么就可以极大地利用 directory-based 的存储空间并提升效率。
Details
在本篇论文的实现中使用 Page 来管理内存块,因为更加细粒度的内存不好管理。当 Page 第一次从主存中加载进来的时候都被设置为私有的,此时一致性协议是被禁用的,当 OS 检测到私有页变成共享的时候,将会触发一致性协议。这对于操作系统来说不需要做特 ...

高速缓存技术(Cache)
Cache 基本原理
直接映射
组相联映射
全相联映射
组相联高速缓存
在组相联 Cache 中,每个块可悲放置的位置数是固定的。每个块有 n 个位置可放的 Cache 被称为 n 路组相联 Cache。一个 n 路组相联 Cache 中有 n 个组,每个组里有 n 块。
以下是被解析了的地址:
123-------------------------------------| Tag | Index | Offset |-------------------------------------
其中 Index 用来选择包含所需地址的组,该组中的所有块都要被索引,所以被选中的组中的所有块的标记并行检索。
首先 Cache 获取到需要读取的地址,随后根据 Index 找到对应的组,根据 Tag 并行找到对应的行(可能出现 Cache Miss),最后根据 Offset 获取到读取的字节数。
Cache 的设计
Cache 模块的数据通路设计
1. 读写操作访问的 Cache 执行过程
第一拍:首先将 Index 读出来同时找到对应的组,并将组里 ...
Chisel 学习笔记
环境配置
下载 jdk 和 sbt,将其加入环境变量中。
Basic Components
Signal Types and Constants
Bit: Bits(8.W)
无符号整数: UInt(8.W)
有符号整数: SInt(10.W)
Conbinational Circuits
val logic = (a & b) | c
123456789val and = a & b // bitwise andval or = a | b // bitwise orval xor = a ˆ b // bitwise xorval not = ˜a // bitwise negationThe arithmetic operations use the standard operators:val add = a + b // additionval sub = a - b // ...

随笔(一)
本来很少写这种文章,但最近一直感觉思绪烦乱但不知道如何排解。看剧看书都不能缓解当前的焦虑,只能靠写文字把我目前的想法写出来,希望可以理清楚一些思路。
这些天一直在家学习,本来是每天计划穿插复习考研和学习技术的,但是在复习考研过程中经常出现不想学习的情况,有时候在学习技术的时候也有出现坚持不下去,不想学习的情况,甚至出现了想放弃考研的想法,我在考研的初期就出现了这种想法。因此在这段时间里,我十分迷茫,乃至痛苦,这和我在上高中一年级时候的心理经历如出一辙。
我认为出现这种问题的原因在于是首先这段时间一直在家里待着,和别人的交流少的可怜,当交流少的时候心理就容易产生变化;另一方面在于我所准备的考研和龙芯杯都是需要长时间准备并且不一定可以出成果的工作,在长时间学习与工作在这种类型的工作上面,难免会发生心态不平衡的情况。
今年将是我在高考之后需要奋尽全力的一年,在高考之后的大一大二基本考试基本水一水就过去了,英语也一直没怎么学习,基本上高中时的习惯和拼劲也不保持了。但尽管如此,考研却不是我唯一的出路,而且考研 9 月份报名,到时可以根据自己的复习情况动态调整考研计划。但同样是因为此原因,自己可以 ...
指令级并行技术
Instruction Level Parallelism(ILP) and Its Exploitation
Concepts and Challenges
有两个大的主题用于开发 ILP:
依赖于硬件去动态开发并行
依赖于软件在编译时静态发现
并行
流水线的 CPI(cycles per instruction)的值是基础 CPI 和所有产生暂停的时间的和:
Pipeline CPI = Ideal pipeline CPI + Structural stalls + Data hazard stalls + Control stalls
在本章中我们主要介绍减少 ideal pipeline CPI 的技术,这会提升解决冒险技术的重要性。
What Is Instruction-Level Parallelism?
最简单和最普通的去提升 ILP 的方式是在循环中实现并行,这种类型的并行叫做 loop level parallesim,接下来是个简单的例子:
12for(i = 0; i <= 999; i = i+1) x[i] & ...
TLB MMU 笔记(基于 MIPS)
TLB MMU
处理器的存储管理部件(MMU)支持虚实地址转换、多进程空间等功能,是通用处理器体现 “通用性” 的重要单元,也是处理器和操作系统交互最密切的部分。
存储管理原理
隐藏和保护
为程序分配连续的内存空间
扩展地址空间
节约物理内存
在 32 位系统中,采用 4 KB 页时,单个完整页表需要 1M 项,对每个进程维护页表需要相当可观的空间代价,因此页表只能放在内存中。若每次进行地址转换时都需要先查询内存,则会对性能产生明显的影响。为了提高页表访问的速度,现代处理器通常包含一个转换后援缓冲器(Translation Lookaside Buffer,TLB)来实现快速的虚实地址转换。TLB 也称页表缓存或者快表,借由局部性原理,存储当前处理器中最近常访问页的页表。一般 TLB 访问与 Cache 访问同时进行,而 TLB 也可以被视为页表的 Cache。TLB 中存储的内容包括虚拟地址、物理地址和保护位,可分别对应于 Cache 的 Tag、Data 和 状态位。
TLB 转换过程如下图所示:
处理器用地址空间标识符(Address Space Identifier, ...

Verilator 学习笔记
Verilator 学习笔记
Introduction
Verilator 是一个 verilog/systemverilog 的仿真器,但是它不能直接代替 vivado xsim 这些事件驱动的仿真器。Verilator 是一个基于周期的仿真器,这意味着它不会评估单个周期内的时间,也不会模拟精确的电路时序。相反,通常每个时钟周期评估一次电路状态,因此无法观察到任何时钟周期内毛刺,并且不支持定时信号延迟。
由于 Verilator 是基于周期的,它不能用于时序仿真、反向注释网表、异步(无时钟)逻辑,或者一般来说任何涉及时间概念的信号变化 - 每当评估电路时,所有输出都会立即切换。
然而,由于时钟边沿之间的一切都被忽略了,Verilator 的模拟运行速度非常快,非常适合模拟具有一个或多个时钟的同步数字逻辑电路的功能,或者用于从 Verilog/SystemVerilog 代码创建软件模型以用于软件开发。
由于 Verilator 是基于周期的仿真器,因此对于 systemVerilog 并非完全支持(我们一般也用不到),同时对于 verilog/systemverilog 的检查很 ...
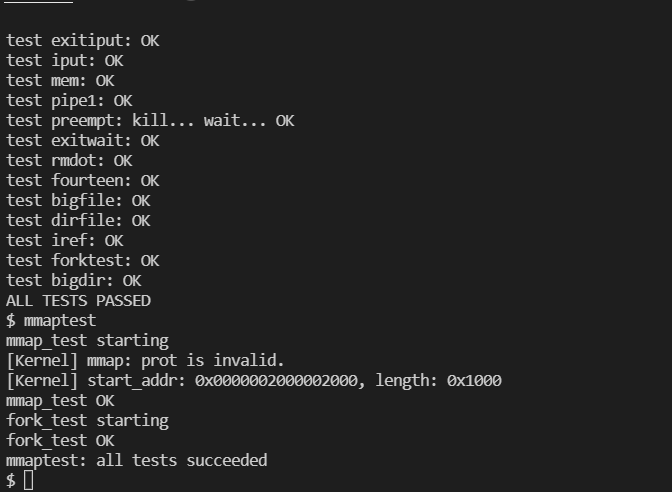
MIT-6.S081-mmap
在本次实验中我们要求实现 mmap 和 munmap 系统调用,在实现之前,我们首先需要了解一下 mmap 系统调用是做什么的。根据 mmap 的描述,mmap 是用来将文件或设备内容映射到内存的。mmap 使用懒加载方法,因为需要读取的文件内容大小很可能要比可使用的物理内存要大,当用户访问页面会造成页错误,此时会产生异常,此时程序跳转到内核态由内核态为错误的页面读入文件并返回用户态继续执行。当文件不再需要的时候需要调用 munmap 解除映射,如果存在对应的标志位的话,还需要进行文件写回操作。mmap 可以由用户态直接访问文件或者设备的内容而不需要内核态与用户态进行拷贝数据,极大提高了 IO 的性能。
接下来,我们来研究一下实现,首先我们需要一个结构体用来保存 mmap 的映射关系,也就是文档中的映射关系,用于在产生异常的时候映射与解除映射,我们添加了 virtual_memory_area 这个结构体:
123456789101112131415161718// 记录 mmap 信息的结构体struct virtual_memory_area { ...
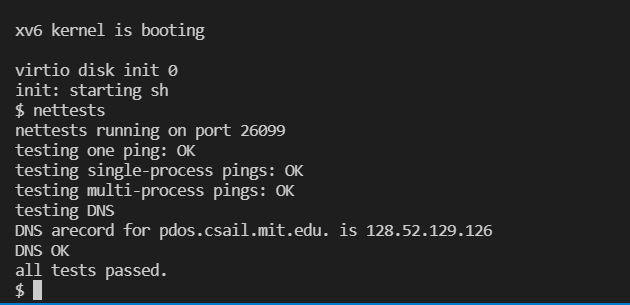
MIT-6.S081 Networking
在本次实验中我们需要自己去实现网卡驱动和网络套接字,在写网卡驱动前我们需要知道网卡收发包的工作原理,再看了文档和查阅了一些资料之后总结了一下。
网卡接收与传输
由这张图我们可以梳理下关于网卡收发包的细节,首先内核需要分配 rx_ring 和 tx_ring 两块环形缓冲区的内存用来接收和发送报文。其中以太网控制器的寄存器记录了关于 rx_ring 和 tx_ring 的详细信息。接收 packet 的细节如下:
内核首先在主存中分配内存缓冲区和环形缓冲区,并由 CPU 将 rx_ring 的详细信息写入以太网控制器
随后 NIC (Network Interface Card) 通过 DMA 获取到下一个可以写入的缓冲区的地址,当 packet 从硬件收到的时候外设通过 DMA 的方式写入对应的内存地址中
当写入内存地址后,硬件将会向 CPU 发生中断,操作系统检测到中断后会调用网卡的异常处理函数
异常处理函数可以通过由以太网控制寄存器映射到操作系统上的内存地址访问寄存器获取到下一个收到但未处理的 packet 的描述符,根据该描述符可以找到对应的缓冲区地址进行读取并传输给上层协 ...
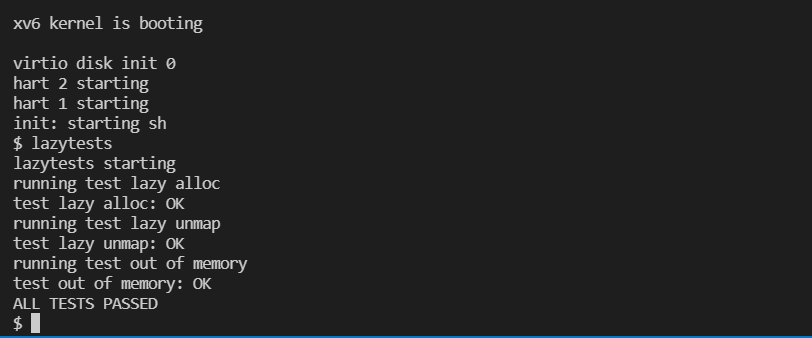
MIT-6.S081 Lazy Page Allocation
在本次实验中我们需要实现内存页懒加载机制,也就是当用户向内核申请内存的时候,内核不需要实际分配内存,而只是增长当前进程的 size,也就是说我们需要修改 sys_sbrk() 系统调用:
12345678910111213141516171819202122// 懒加载,在这里仅仅改变进程记录的内存大小的值// 而并不实际分配uint64sys_sbrk(void){ int addr; int n; if(argint(0, &n) < 0) return -1; addr = myproc()->sz; if (n < 0) { if(growproc(n) < 0) return -1; }else{ if(addr + n >= MAXVA){ return -1; } myproc()->sz = addr + n; } retu ...